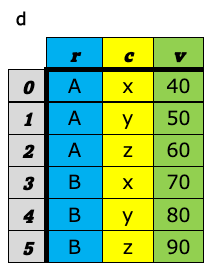
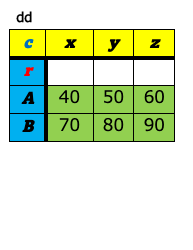
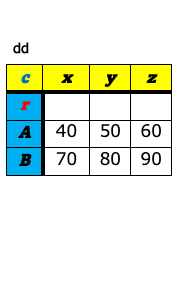
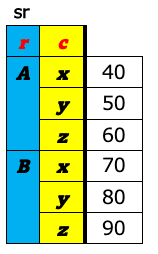
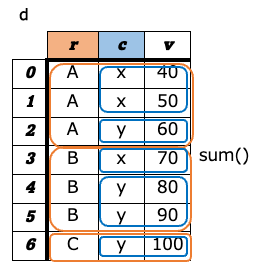
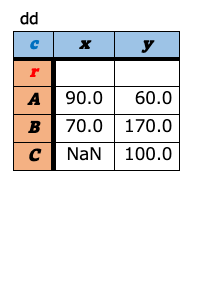
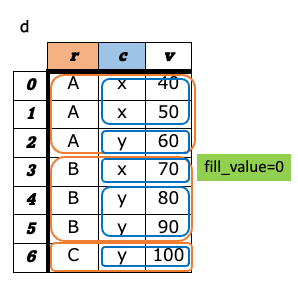
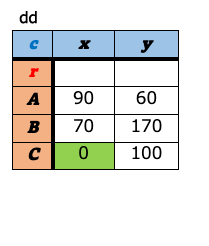
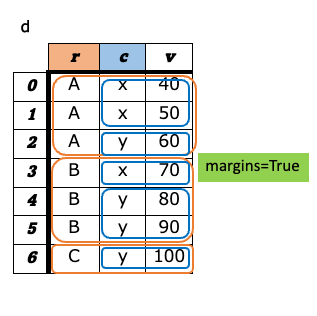
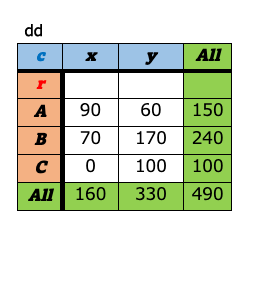
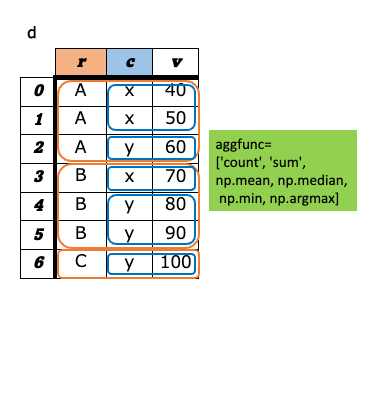
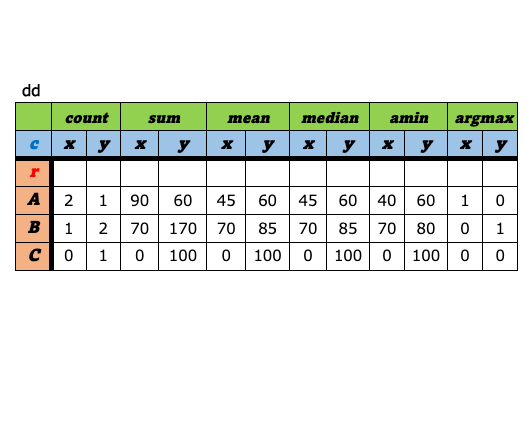
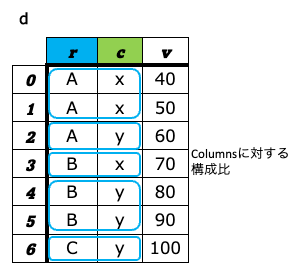
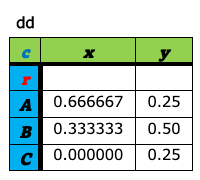
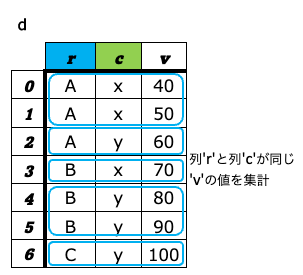
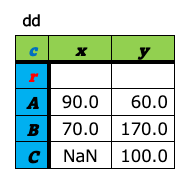
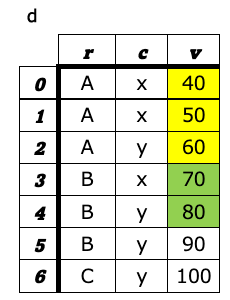
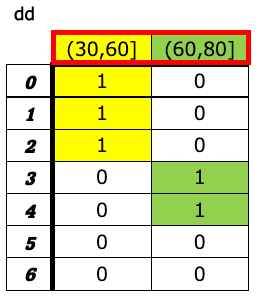
a-8. ピボット¶
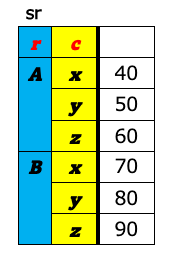
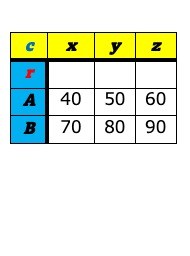
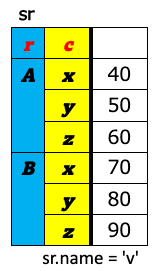
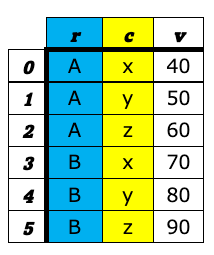
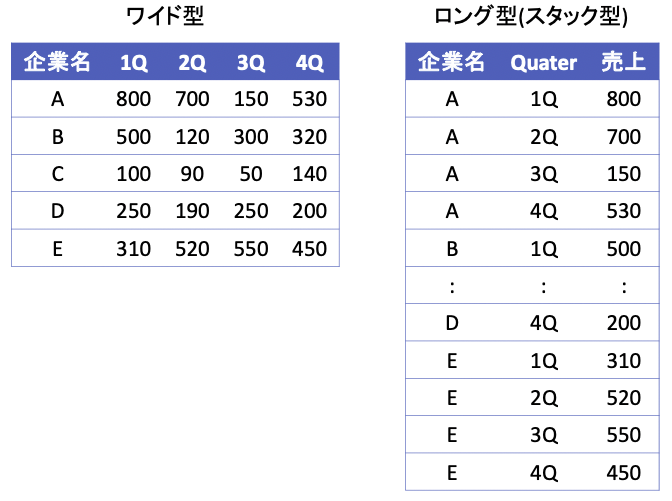
データ分析の世界で表構造のデータを扱う時、大きく分けて、ワイド型(wide format)とロング型(long format)(もしくは、スタック型(stacked format))と呼ばれる2つの表のフォーマットを意識しておくとよい。 これら2つの違いは、キー(値を唯一識別するための項目)を列名として持つか(ワイド型)、1つの列の値として持つか(ロング型)の違いである。 下図の左がワイド型で右がロング型の例である。いずれも「売上」という値を識別するためのキー項目として企業名(A〜E)とQuater(1Q〜4Q)があり、どちらの表も内容的には変わらず、フォーマットが違うだけである。
ロング型の利点は、キー項目を列で持っているために、groupby()などのキー単位の処理を伴う処理がやりやすいことにある。
一方でワイド型は、回帰モデルなどの入力データで利用されるフォーマットである(1行1サンプル)。
前処理はロング型で行い、モデル構築やデータ内容の表示といった分析の最終工程でワイド型が利用されるのが典型的なパターンである。
目次¶
1. ワイド型-ロング型の変換(pivot, stack, unstack)
2. 集計を伴うpivot(pivot_table)
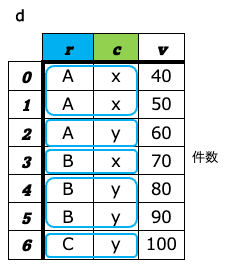
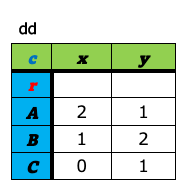
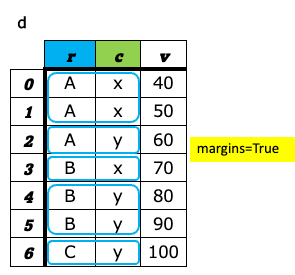
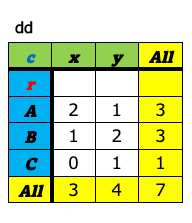
3. 件数集計(cross_table)
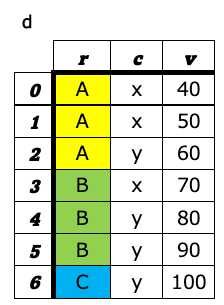
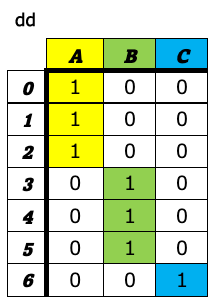
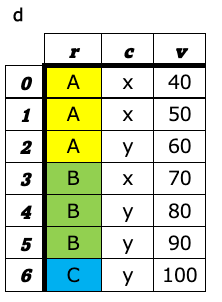
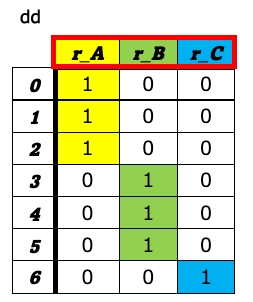
4. ダミー変数の生成(get_dummies)
関連ドキュメント¶
APIリファレンス¶
- DataFrame.pivot
- DataFrame.stack
- DataFrame.unstack
- DataFrame.pivot_table
- pandas.unstack
- Series.str.get_dummies